



 Live Chat
Live Chat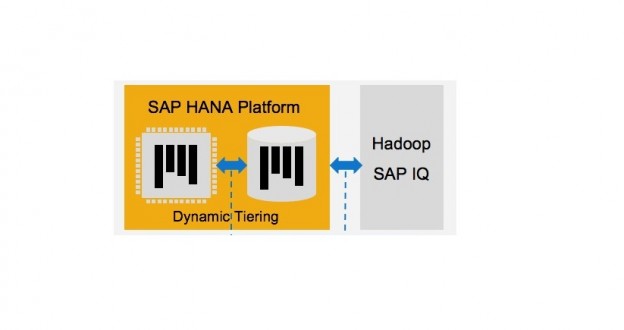
SAP HANA and Hadoop together make one of the best technological trend of today’s world. Given the amount of efforts that has been put into it, SAP Hadoop integration is one of the smoothest you will have in today’s world.
Without a doubt, technology has excellent ability of shaping the world. Nowadays, Big Data is the most famous technology trend, which will make an impact on the world in the near future. It is assumed that by the year 2020, the stored data amount will be 50 times bigger than the present amount. Basically, SAP HANA is a strategic platform that combines or unifies all the data. SAP HANA is great for applications’ central data management as it is capable and open in managing transactional and analytics workloads on a single platform. Furthermore, sap hadoop integration makes easy to unify it with different technologies like Hadoop and others in order to obtain effective and suitable landscape of Big Data.
SAP HANA smart data integration has also become smooth, thanks to the increased proficiency of those involved in the development and research of these tools. More and more companies are increasingly migrating toward SAP HANA, though a few loose ends remain, which can only be met if corporate world lends it helping hand.
Integrating Hadoop Power with SAP HANA –
Earlier, SAP has announced SAP HANA Vora. This permits customers in order to efficiently combine the business data through SAP HANA along with the data via telephone networks, industrial sensors as well as different data sources, saved in the Apache Spark. It is an essential step for the SAP in Big Data. SAP has over 300 applications within Fiori landscape. Many of the apps belong to analytical applications’ category.
SAP to Hadoop and Hadoop to SAP isn’t an easy migration. First, there are a number of problems associated with each platform, so migrating from one to the other isn’t always easy. Second, no matter how many people come forward, the numbers will always remain pretty low in each.
The self-service tool of SAP is Lumira SAP that visualizes and analyzes the data. Utilizing this tool, users could implement advanced analytics in order to gain insights without any need of IT. Each users could make data visualizations over screen instantly. The tool of Datavard called the Glue tasks as middleware. Built on ABAP, while it can reach in the Hadoop in order to move data alternating in between Hadoop and SAP. Glue effortlessly integrates Big Data with the SAP technology and it is a solution that permits the users in order to contact Hadoop via SAP GUI and ABAP.

SAP HANA with Hadoop means infinite scale and instant access.
SAP HANA platform could be integrated along with Hadoop utilizing different approaches and solutions, as per the needs of use case. The SAP solutions that must be considered for integration are –
– SAP BO BI Platform I Lumira
– SAP BO Data Services
– SAP HANA Smart Data Access
– SAP HANA Enterprise Information Management
– SAP HANA Data Warehousing Foundation
– SAP Near-Line Storage
– SAP HANA Spark Controller
– SAP Vora
SAP HANA Cloud could leverage the HANA Smart Data Access in order to join data from the Hadoop without copying remote data in the HANA. The SDA allows data federation (write/read) utilizing the virtual tables as well as supports Apache Spark and Apache Hadoop/Hive as the remote data sources along with most database systems like SAP ASE, SAP IQ, IBM DB2, Teradata, MS SQL, Oracle and IBM Netezza.
Hadoop could be utilized as remote data source for the SAP HANA’ virtual tables utilizing the below-mentioned adaptors (in-built in the HANA) –
– Spark/Hadoop ODBC Adaptor – Need to install the Apache Hive/Spark ODBC Drivers and Unix ODBC drivers over HANA server
– Hadoop Adaptor (WebHDFS)
– SPARK SQL Adaptor – Needs installation of the SAP HANA Spark Controller over Hadoop Cluster
– Vora Adaptor
In addition, SAP HANA could leverage the HANA Smart Data Integration in order to replicate the needed data through Hadoop in the HANA. SDI offers adaptor SDK and pre-built adaptors to connect a wide range of data sources, such as Hadoop. The HANA SDI needs installation of the Data Provisioning Agent (consisting standard adaptors) as well as inherent drivers for remote data source, going on the machine. The SAP HANA XS engine made on DWF-DLM could relocate the data as of HANA to HANA Extension Nodes, HANA Dynamic Tiering, and Hadoop through Spark Controller/Spark SQL adaptor, and SAP IQ.
SAP HANA Vora is in-memory engine, which runs on Apache Spark framework as well as offers interactive analytics over Hadoop data. The data in Vora could be accessed within HANA directly through Spark SQL Adaptor or Vora Adaptor. It supports Cloudera, MapR and Hortonworks.
SAP BODS (BO Data Services) is comprehensive data integration/replication solution. It has abilities to access the data in the Hadoop, process the datasets in the Hadoop, push the data to Hadoop, push the ETL jobs towards Hadoop utilizing Spark/Hive queries, MapReduce jobs, pig scripts as well as do direct interaction through native OS or HDFS files. The SAP SLT doesn’t possess native abilities to connect with Hadoop.
SAP Business Objects (Lumira, BI Platform and Crystal Reports) could visualize and access the data through Hadoop (Hive-Spark-Impala-SAP Vora) along with a capability to combine with the data via non-SAP sources and SAP HANA. The SAP BO apps utilize generic connectors or in-built JDBC/ODBC drivers to connect with Hadoop ecosystem.
Extract Transform Load (ETL) I Online Transaction Processing (OLTP) I Online Analytical Processing (OLAP)
Read More at : Buoyant Benefits of SAP Archiving in Hadoop
So far, it is understood that Hadoop could store a large amount of the data. Hadoop is suitable for storing the unstructured data and also good for operating large files as well as tolerant to software and hardware failures. However, the challenge with the Hadoop is receiving information from the huge data within real time. Therefore, with SAP hana hadoop integration of Hadoop could combine the structured as well as unstructured data that could be moved to the SAP HANA through HANA Connector/Hadoop.
– Security and Simplification
Hadoop Vs SAP HANA
It won’t be easy determining the winner when it comes to a contest between Hadoop and SAP HANA. SAP HANA has the overall best user interface whereas Hadoop is said to have better support.
Utilizing SAP HANA as joining platform for the data simplifies software and system administration lifecycle management, therefore helping in order to minimize the overall ownership cost.
HANA is relational Massive Parallel Processing (MPP) database, relies heavily over in-memory data storage. The HANA is ACID compliant as well as follows the ANSI SQL standards with stringent hardware specifications.
When talking about Hadoop, it is a suite of open-source distributed computing tools, positioned over HDFS as well as Hadoop map-reduce (API). It is made in order to work over any specification’ commodity hardware.
Whereas, HANA possesses the ability of connecting to Hadoop utilizing Smart Data Access, from where it could pull the data through Hadoop and merge it along with org-data as well as provide the meaningful insights.
SAP HANA Hadoop can be used to store as well as analyze the data that comes out of the organization, mainly unstructured from the customers as tweets, likes, comments from website and social media.
– Technology
As it is known by everybody that HANA is the software and Big Data is concept. So, they could not be compared. The platform of Big Data performs complex analysis. HANA utilizes Hadoop as Big DATA platform whenever it has to process different data types.
All-in-all, people find it difficult to relate to these terms and get confused as both of the platforms uses Big Data. These technologies can together create an effective Big Data platform.
Sanjay Poddar is a prolific writer whose in-depth knowledge on tech sector and curiosity to explore the unexplored has helped him to become an asset to the company. Apart from technology, he has covered various domains that he is keen to explore.
Nice blog! I have gained good knowledge about Hadoop.
This is really interesting, You are a very skilled blogger. I’ve joined your rss feed and look forward to seeking more of your magnificent post. Also, I have shared your site in my social networks!